Trump or Computer Dump?
In early 2019 OpenAI published some research showing that large language models, when trained on colossal amounts of text, begin to behave unpredictably intelligently on tasks they weren’t originally trained on. Humorously, part of the original dataset for the model was scraped from Reddit - which isn’t always known to be the home of constructive conversation and accurate information so it’s even more surprising how good their model was!
In 2020, while taking an NLP, course I thought it would be fun to finetune GPT-2 on a corpus of then President Trump’s tweets seeing as he has such a distinct style and voice. I obtained his tweets from the super convenient Trump Twitter Archive which contained ~56,500 of his tweets from 2009 until he was banned from the platform on January 8th, 2021.
The original project took me around 3 weeks if I remember correctly and this weekend as I was dog sitting I remembered that project and got excited about trying to recreate it with the latest tools available, namely HuggingFace. It was awesome to have a benchmark to compare against to measure and truly appreciate the efficiency and ergonomics of HuggingFace’s transformers library. I was able to replicate the finetuning through a short notebook + host it using gradio on a HuggingFace space in just a couple of days.
Finetuning with HuggingFace Transformers
First I defined some hyperparams for training:
# define some params for model
batch_size = 8
epochs = 15
learning_rate = 5e-4
epsilon = 1e-8
warmup_steps = 1e2
sample_every = 100 # produce sample output every 100 steps
max_length = 140 # max length used in generate() method of model
Assuming the twitter data is downloaded and preprocessed, we need to tokenize the tweets (which means assign a unique int to every word or character) and load them into a dataloader. The AutoTokenizer is really nice because it uses the right tokenizer for any specific model available on HuggingFace if you give it a model name e.g."gpt2-medium".
from transformers import (
AutoTokenizer
TextDataset,
DataCollatorForLanguageModeling
)
# create tokenized datasets
tokenizer = AutoTokenizer.from_pretrained(
"gpt2-medium",
pad_token='<|endoftext|>'
)
# custom load_dataset function because there are no labels
def load_dataset(train_path, dev_path, tokenizer):
block_size = 128
# block_size = tokenizer.model_max_length
train_dataset = TextDataset(
tokenizer=tokenizer,
file_path=train_path,
block_size=block_size)
dev_dataset = TextDataset(
tokenizer=tokenizer,
file_path=dev_path,
block_size=block_size)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False,
)
return train_dataset, dev_dataset, data_collator
train_dataset, dev_dataset, data_collator = load_dataset(
train_path, dev_path, tokenizer
)
Now we can instantiate the model, optimizer, and learning rate scheduler. I’d never experimented with dynamically changing the learning rate during training so using get_linear_schedule_with_warmup() was exciting. The resulting learning rate vs. epochs graph looked like this:
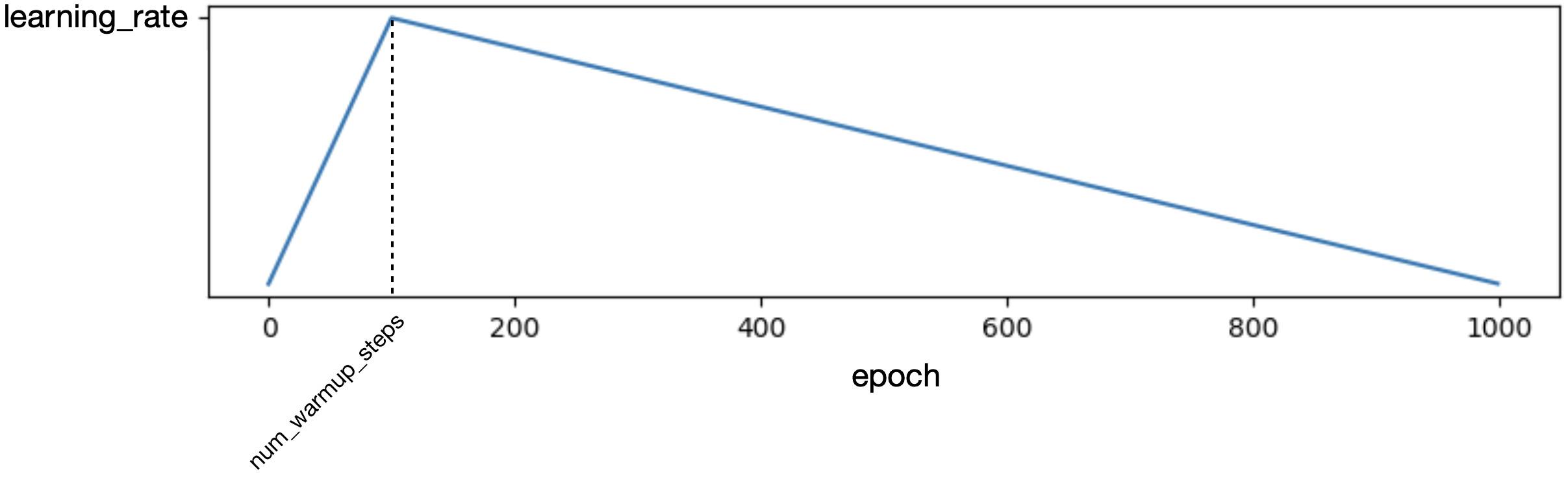
which shows a delay in reaching the learning_rate by num_epoch_steps and then a slow decrease until the nth epoch.
from transformers import (
AutoModelWithLMHead,
get_linear_schedule_with_warmup,
)
# AutoModelWithLMHead will pick GPT-2 weights from name
model = AutoModelWithLMHead.from_pretrained(
model_name,
cache_dir=Path('cache').resolve()
)
# necessary because of additional bos, eos, pad tokens to embeddings
model.resize_token_embeddings(len(tokenizer))
# create optimizer and learning rate schedule
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, eps=epsilon)
training_steps = len(train_dataset) * epochs
# adjust learning rate during training
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps = warmup_steps,
num_training_steps = training_steps
)
Finally we can instantiate a TrainingArguments object which holds hyperparams and then run training from the Trainer object. This also prints out a pretty printed loss vs. step table.
from transformers import (
Trainer,
TrainingArguments,
)
training_args = TrainingArguments(
output_dir="./gpt-2-medium-trump",
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
eval_steps = 400, # n update steps between two evaluations
save_steps=800, # n steps per model save
warmup_steps=500, # n warmup steps for learning rate scheduler
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
)
# train & save model run after done
trainer.train()
trainer.save_model()
Inference with HuggingFace Transformers
Inference was even easier than training as all you need to do is set up a pipeline for the model:
from transformers import pipeline
trump = pipeline(
"text-generation",
model="./gpt-2-medium-trump",
tokenizer=tokenizer,
config={"max_length":max_length} # n tokens
)
Trump at your fingertips
In: trump("Today I'll be")[0]["generated_text"]
Out: "Today I'll be rallying w/ @FEMA, First Responders, Law Enforcement,
and First Responders of Puerto Rico to help those most affected by the
#IrmaFlood.https://t.co/gsFSghkmdM"